Thinking about scaling your Metadata & Data Quality with GenAI? - Here is how
by Emmanuel Asimadi - Data & AI Leader | 6min read
In today’s data-driven world, scaling insights requires more than data — it demands context and trust. Even more so as machines increasingly become capable of generating and consuming insights — metadata and data quality have become essential enablers of sustainable data value creation.
Without this context and trust, all efforts at democratising insights - for humans and now machines - are futile.
Traditionally, creating Metadata and Quality Rules even for critical data elements has been a tedious, siloed and manual exercise. Subject Matter Experts (SMEs) manually generate attribute definitions and business rules while quality analyst and engineers encode those rules into data pipelines or quality systems - a challenging effort when scaling metadata and data quality across the enterprise.
With Generative AI (GenAI), we now have the tools to scale and automate these capabilities like never before! Platforms such as Databricks, Atlan and others offer built-in features to automatically generate column and table descriptions from the schema. However AI-generated annotations aren’t perfect — only you truly know what the column b_id represents! in your dataset
databrick’s note on ai generated metadata.
AI-generated comments may not be perfect, but they provide a significant productivity boost for metadata efforts. To ensure quality, humans (Data Owners & Stewards) must review these comments before publishing. One approach would be to publish AI-generated comments as drafts - making them visible to the organisation (with a clear disclaimer) - and then crowdsource improvements. After the initial heavy lifting, improving metadata becomes a continuous activity.
In this article I explore taking this further by targeting the initial large-scale effort at creating high quality metadata and quality rules specific to your enterprise. so you are in control of the generation process to your competitive advantage.
To take this to the next level, a number of items must be addressed
Knowing where to start — to create business value, leverage and scale metadata and quality efforts quickly.
Customising your metadata — your metadata could be your differentiator; you want to be able to flexibly generate it in a way that meets your organisation’s needs.
Consistency — With different domains owning metadata, without shared standards, metadata efforts can be fragmented not (re-)useable across the enterprise.
Scale — with generative AI, you can truly scale your metadata and data quality efforts when done right.
Where To Start?
Start with the business objectives and what you would like to achieve with your metadata efforts. It’s also worth beginning with metadata, since it can be leveraged in your Data Quality initiatives rather than running them in parallel and duplicating efforts. As you would see in this example the effort in defining and implementing quality rules could be more than halved done this way. Here, our focus is to enable data analytics, science and AI through Metadata. Other use cases include information exchange.
Metadata exists to support the discovery, interpretation, and use of data, providing much-needed context.
Done right, your metadata can enable:
-
Data Discovery & Interpretation
As a data consumer, you can easily discover, interpret and use the data to create value.
-
Data Privacy & Security
The enterprise knows each data asset’s sensitivity and criticality, enabling attribute-based access control (ABAC) or other automation based on tags.
-
Scaling Data Quality
Data Quality rules enable you to monitor and manage the health of your data assets at scale. In this approach we scale quality by deriving it automatically from metadata.
-
Enabling AI Tools & Agents
To be reliable and support the democratisation of insights, AI-driven analytics tools (e.g. Thoughtspot, Databricks AI/BI, Tableau Pulse, Amazon Q) - require robust metadata and trusted data.
Scaling Metadata & Quality: TPC-H Dataset Example
To illustrate, let’s assume our organisation’s data to be the TPC-H dataset. We will proceed to AI-generate much of its metadata and quality rules to demonstrate the potential of enterprise-scale Metadata and Data Quality rules generation. For this trivial example we use the Customer and Orders table.
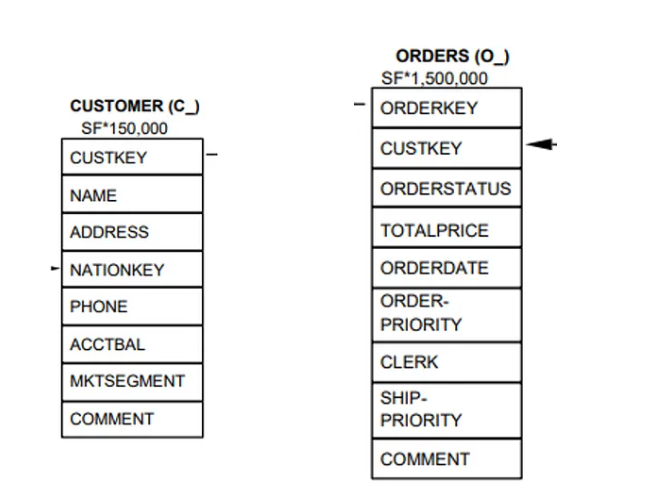
TASK 1 - Generate missing data descriptions according to enterprise requirement
With an appropriate prompt and schema we can obtain column descriptions that support the discovery, interpretation, and use to the data. By supplying the LLM with existing column descriptions and schema data, it gains enough* context to infer (more like guess) the missing description for columns and table.
This generated metadata can be treated as draft until certified by data owner or steward. In Business-as-Usual (BAU) operations, a continuous feedback process should allow SMEs and Data Consumers to request or make improvements safely.
In the prompt I included the requirement for column aliases (synonyms) to enable AI-driven visualisation applications - such as ThoughtSpot, Databricks AI/BI or tableau pulse - better handle user queries that use alternative names. This scales analytics by enabling business users to ask questions without needing to know underlying column names.


Task 2 - Generate tags for the columns to support the management of the asset.
Tags are another class of metadata that significantly support asset management. Tags are flexible, with that flexibility can come chaos and dysfunction if not standardised enterprise-wide. In some implementations I have seen tags implemented as simple value tags (e.g PII, Sensitive, Company Confidential). My preference however is to implement tags as Key-Value pairs for rigorous consistency.
Tags support asset management at scale - for example, through ABAC. we can flexibly ensure that data tagged as PII is only visible to approved groups.
To manage tags enterprise-wide, we require a taxonomy that defines allowable keys and values for tagging attributes. Below is an example taxonomy which we then use to auto-generate tags for our dataset (e.g. for the customer table).


Tags include categories such as data_class, criticality among others. The critically tag identifies Critical Data Elements (CDEs), attributes that are vital based on their downstream applications or the impact of quality issues .
As described above these attributes can form the bases of access control at scale — and we have been able to AI-generate them. Note that this will require human-in-the-loop to validate and implement, however the effort required is orders of magnitude lower and now feasible at the level of the enterprise.
Task 3 - Now use the metadata to scale your data quality efforts.
Using the metadata data, we can now generate and apply data quality rules to our dataset - enabling continuous monitoring and management. Historically, defining and running these rules was not trivial, so starting with CDEs was advised. In many cases, monitoring CDE quality alone already delivers significant enterprise value.
In the example, I ask chatgpt to generate quality rules for Critical Data Elements. These rules can be expressed as SQL checks or in a more declarative syntax like Great Expectation. In minutes you can set up your dataset with quality monitoring whether we rely on sql based tools or opensource quality monitoring tools like Great Expectations. Often, Critical Data Elements Quality might be all you need.

Final Thoughts
GenAI has unbelievably made things feasible that were not feasible before — Metadata and Data Quality scale to the enterprise is one of those. With less than 15% of the effort we can leverage GenAI to scale Data Quality and Metadata to the enterprise. The value of which are numerous including enabling analytics, streamlined asset management and greater value from high-quality data.
Very exiting application of GenAI and I look forward to what you are able to do with it.
Need Support with your Data Governance, AI & Analytics efforts ? Do not hesitate to reach out or connect on linkedin